
While they say that “necessity is the mother of invention,” frustration is surely a paternal grandfather. And as a long-time fantasy football participant, I’d say one of its most frustrating aspects is seeing your team’s kicker perform poorly, even when the offense they’re on might be scoring well. It’s a universal experience and well understood that kicker scoring is considered so unpredictable, most outlets advocate not even drafting one for your team and just picking one you feel best about on a week-to-week basis. Sites do their best to provide projections to help you select, but exactly how well do those perform?
To assess the current state of kicker point total projection, I’ll assess a publicly available combination of predictions released by ESPN.com and NFL.com, which both serve as platforms for fantasy leagues and provide predictions for its players. I’ll compare it with errors coming from 2 crude strategies: 1) using cumulative averages for a kicker during the season, and 2) one using cumulative averages from the opposing team for points given up to kickers during the season.
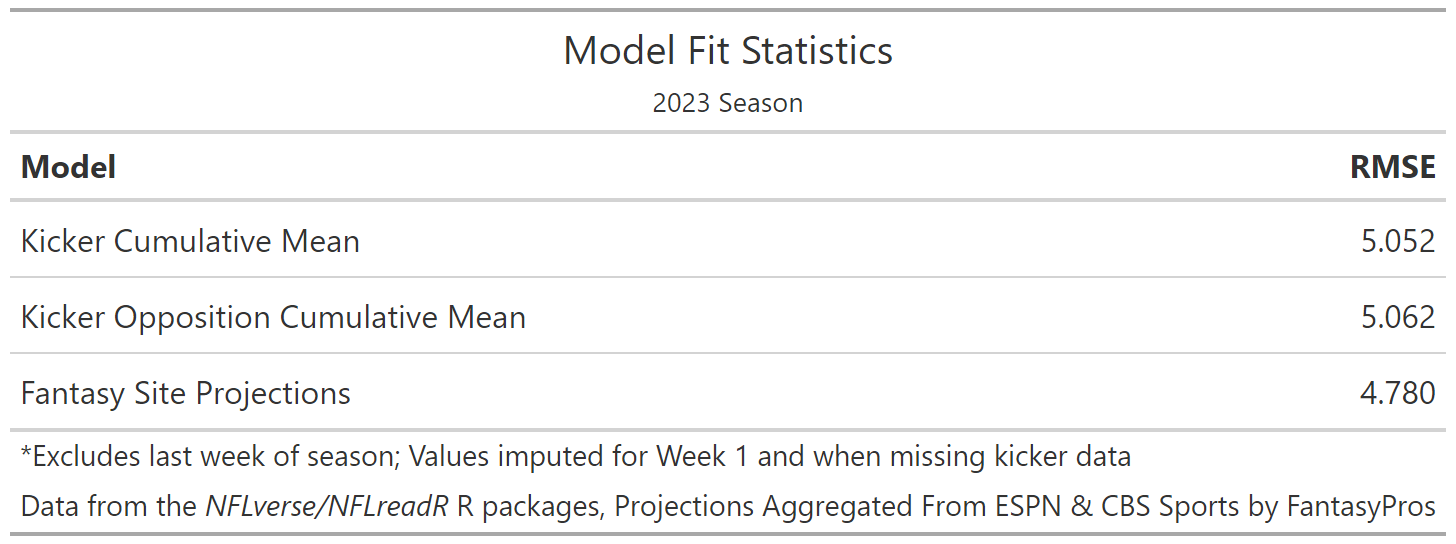
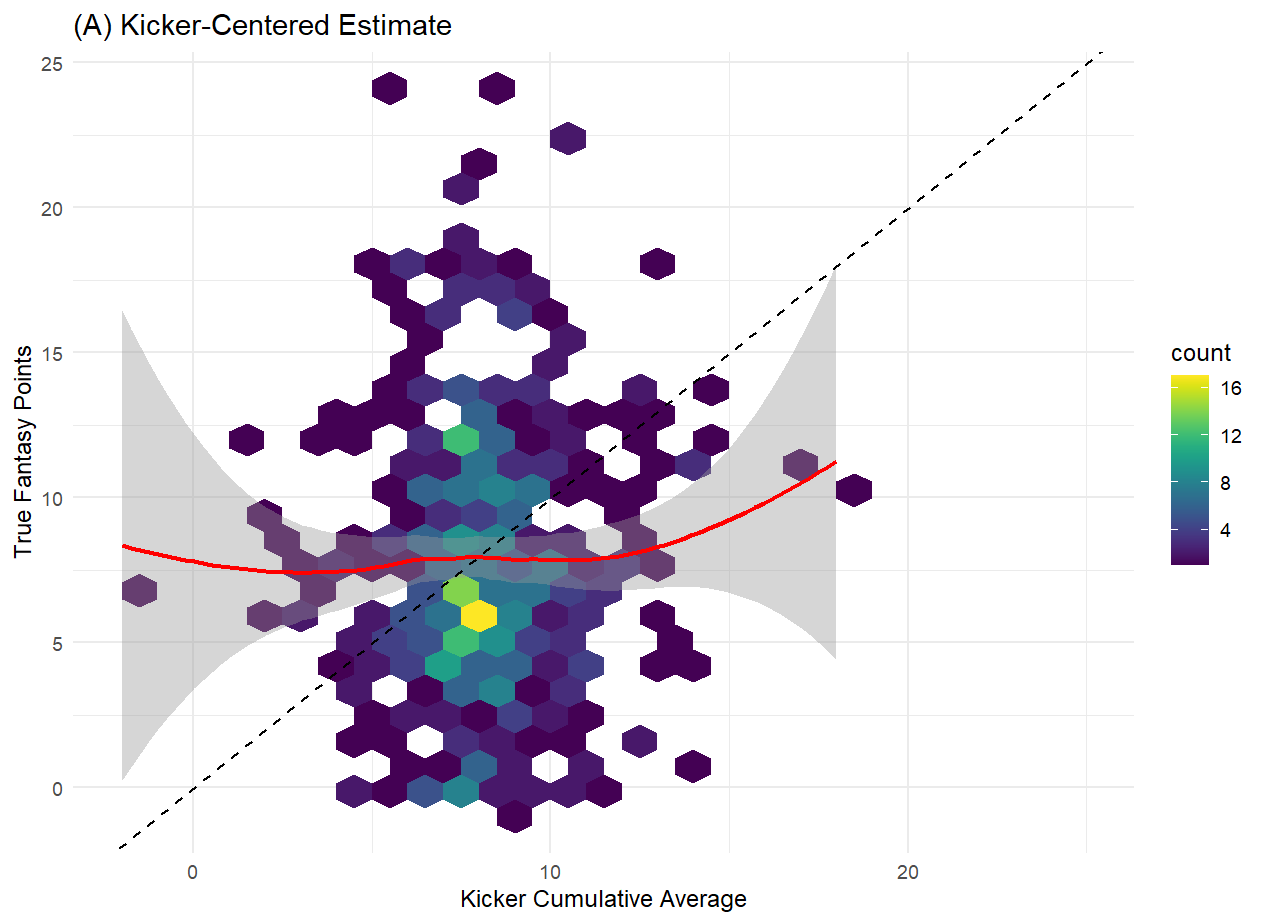
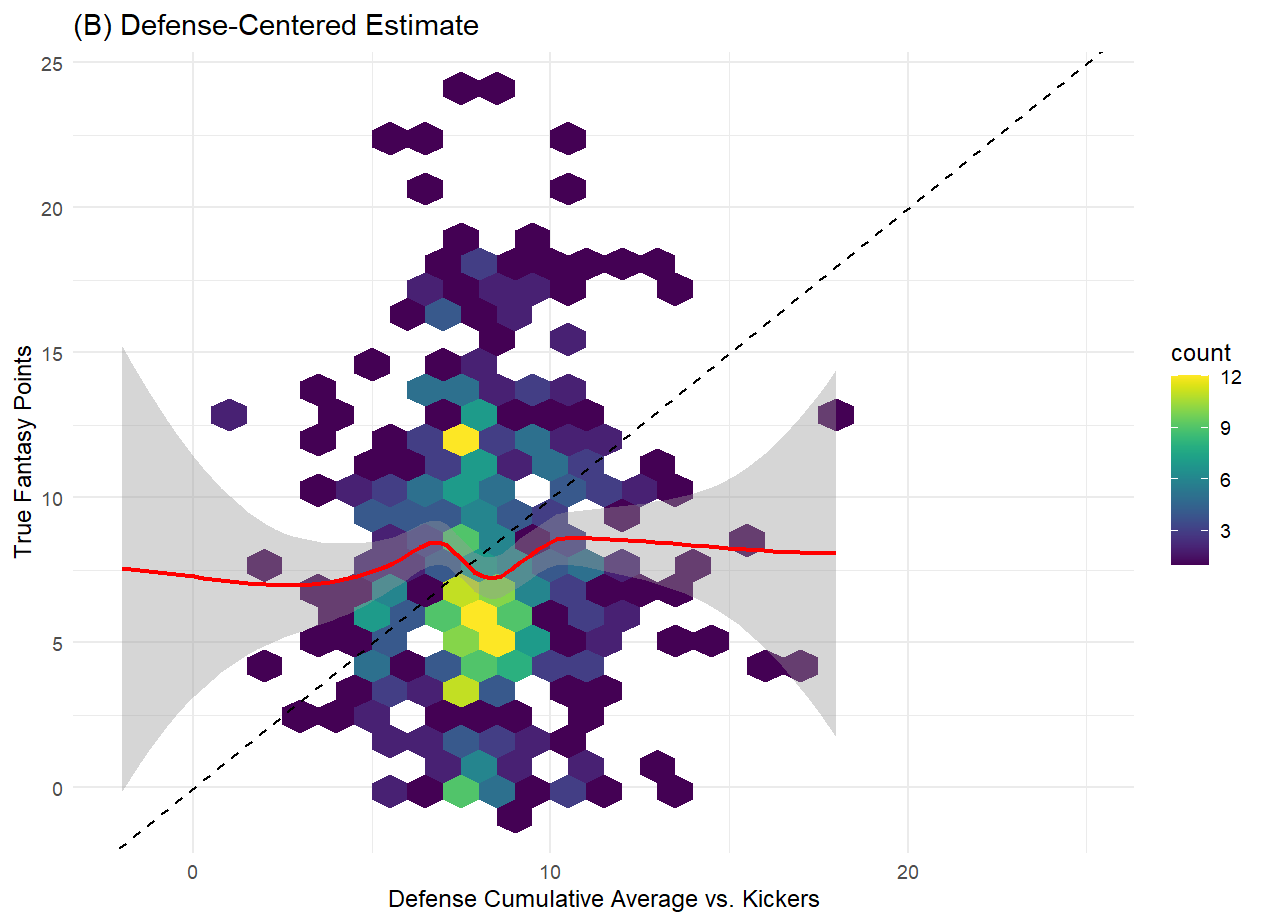
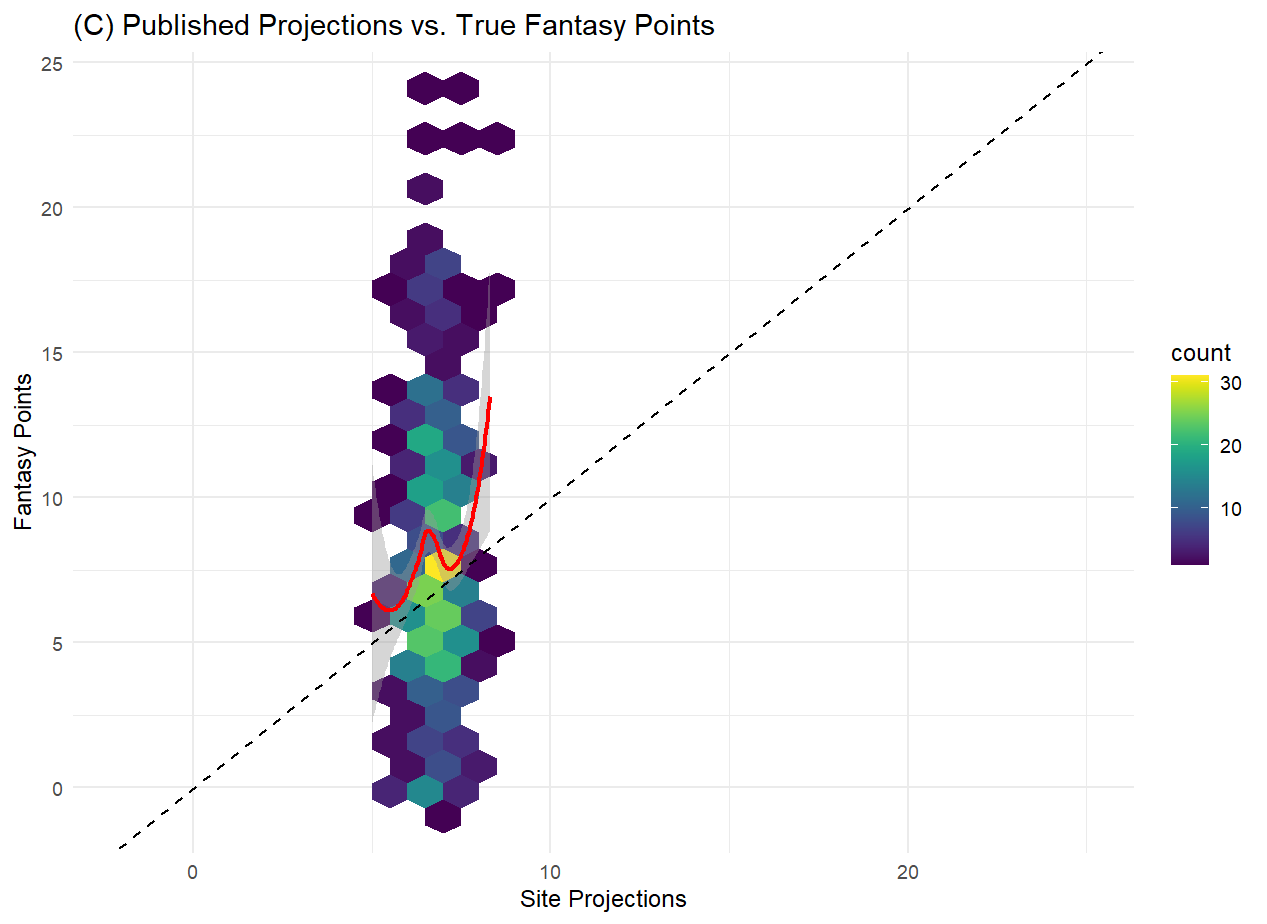
What we find for the most recent season is that the combination of public predictions from ESPN and NFL do, on a game-by-game basis, outperform lagged cumulative averages of a kicker’s performance, and of an opposing team’s performance against kickers. Unlike the cumulative averages, which demonstrate little relationship with the actual kicker scoring, we do see that the site projections do at least show some correlation with kicker scores.
However, given the fact that those projections have some trouble parsing out the kickers that ultimately fall farther away from the mean, a better model should be achievable. Additionally, those projections have a very narrow range and don’t differentiate much between kickers, which doesn’t inspire confidence when using them to make a single selection for your team. The saving grace of those projections might be the fact that the highest projected kickers also appear to be ultimately the highest scorers, and that end of the distribution is the one players are most interested in. While it’s possible that one or both website prediction models perform better individually than does the combination of the two provided by FantasyPros, there seems to be a lot of room for improvement. Given the structure of the problem at hand, with a continuous quantity to be predicted and all manner of related data points available to us, a machine learning approach should do well here.
A New Model (or Few)
Knowing what we know about how kickers accumulate fantasy points, we can come up with a number of candidate predictors to inform our model. There should be factors inherent to the kicker (accuracy and ability to kick from distance), the kicks themselves (e.g. wind/weather), and the offensive and defensive gameplay that results in a kicker into position to attempt a kick (e.g. offensive/defensive scoring potential, propensity to score touchdowns vs. attempt field goals). We can use some variables sourced through the nflreadr package and craft others to fuel our model.
Some of these variables may exhibit more complicated, non-linear relationships with kicker success. As mentioned before, a successful offense should yield more opportunities for a kicker to score, but wildly successful offenses might score more touchdowns and reduce the number of field goals those kickers kick. A kicker might also seemingly be very accurate, which should be related to higher kicker scoring, but that those accuracy stats might be due to a distrust of that kicker’s ability to kick long distance field goals, which limits scoring opportunities. So it’s likely that we’d benefit from a fair amount of model flexibility.
Given that supposition, we’ll use the tidymodels framework to apply an array of different machine learning techniques to develop our models:
linear regression (ridge regression, elastic net regression)
random forest for ensemble decision tree-based learning
XGBoost for a gradient-boosted version of tree-based learning
k-nearest neighbor models
support vector models (radial basis function)
bagged multilayer perceptrons (ensemble deep learner)
a stack of some or possibly all above models
Using a bit of domain knowledge and logical reasoning, we’ll identify and test a number of potentially predictive features. These would include kicker characteristics, characteristics of their team, characteristics of the opposing team, and external characteristics of the specific to the game. Because these are for generating predictions week-to-week, we’ll use cumulative averages for certain features to ensure that we’re not using information that would have been unavailable to other predictors.
At this point, I’ll hand-wave some of the exploratory data analysis and initial attempts and just mention that, after an aggressive amount of feature engineering and exploratory data analysis, we narrowed focus to a few predictors to balance predictive value and overfitting. After the process, we’ve settled on:
Predicted points scored for the kicker’s team
- Higher points expected means more expected field goals and extra points
4th down try rate
- Measures offensive aggressiveness, impacting likelihood of field goal attempts in certain situations
Kicker fantasy point avg
- Simple proxy for past kicker performance
Predicted points scored for the team opposing the kicker
- Higher points expected should relate to fewer points, field position, and consequently better field position and more possessions for the kicking team
Defense fantasy point avg vs kickers
- Simple predictive proxy for past performance of defense against kickers
Max distance kicker
- Serves as a proxy for kicker’s long range ability
Kicker FG percentage for the season
- Measure of kicker accuracy
Kicker XP percentage for the season
- Measure of kicker short range accuracy
Stadium type (outdoors, dome, closed roof, open roof)
- Describes how controlled the weather environment is
Wind speed
Kicker home or away stadium
Week
Season
We applied our machine learning algorithms over data covering 5 seasons (2018-2022), holding out 2023 for testing purposes. We split those 5 seasons into 10 folds to apply cross-validation, with the hopes of identifying models with low root mean squared errors (RMSE).
For SVM, random forest, XGBoost, and bagged MLP, we use Bayesian optimization of model tuning to reduce run time and increasing the likelihood of finding better-fitting models. For the remaining models, we use a Latin hypercube-generated grid search.
Model Selection
While our process created the best fits for the training data using the random forest, KNN models, applying them to 2023 data showed a strong degree of overfitting (Table 2). That issue persisted despite a number of subsequent attempts to alter our parameter tuning and the amount of information available in each cross-validation fold. Ultimately, despite concerns about non-linear relationships for many of the variables, the models that ultimately fit 2023 data best were the linear regression models, though they were followed closely by our tree-based ensemble models. The stack model also produced a similar fit to the test set, but did not demonstrate any real improvement over the individual components as hoped for an ensemble of models. We chose to exclude the random forest and KNN methods because of their overfitting tendencies, but this admittedly didn’t change the model fit appreciably compared to stacks permitting the inclusion of any of the models.
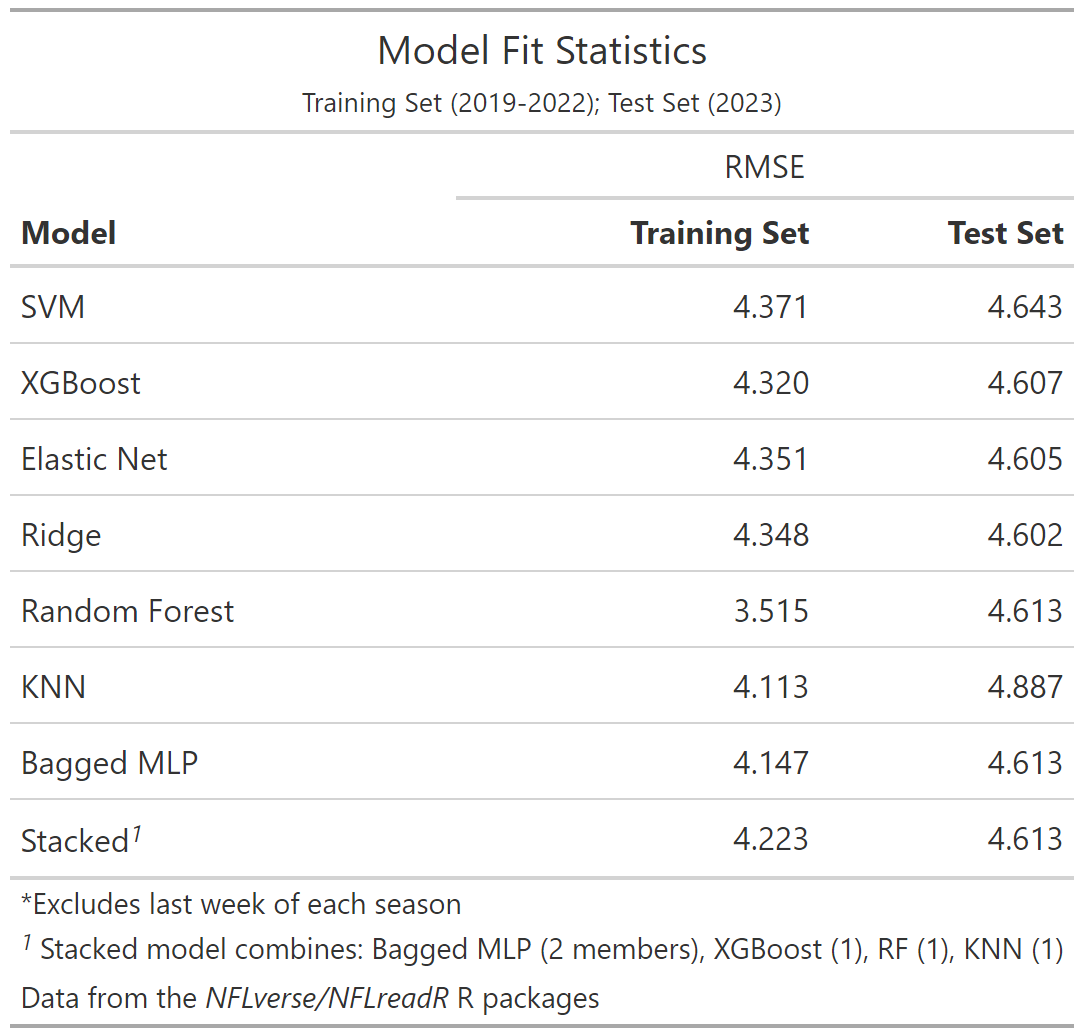
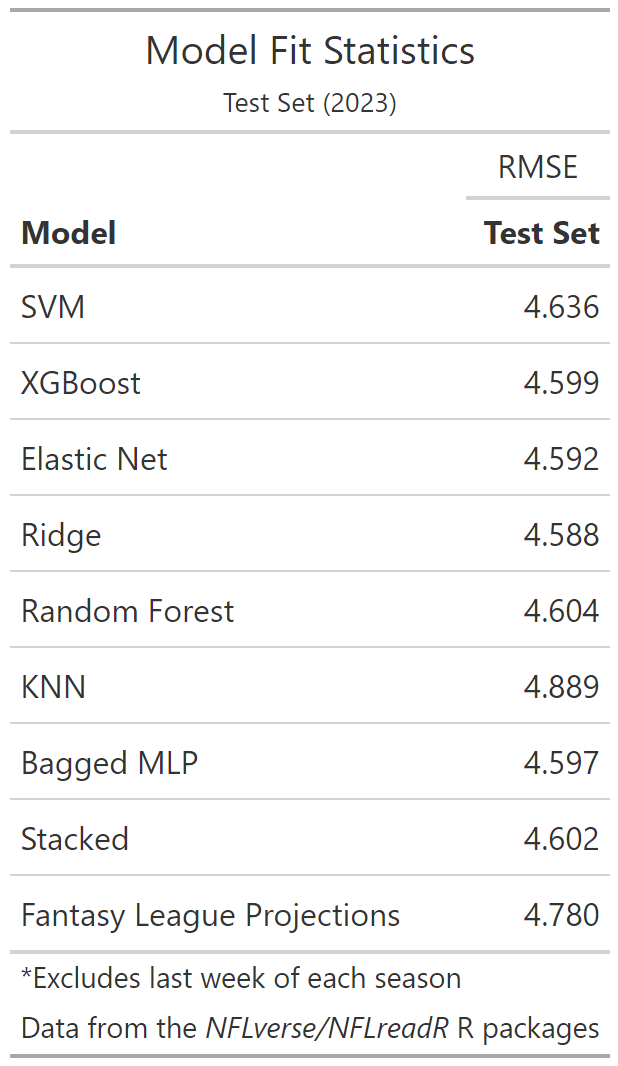
Direct comparisons with the fantasy site projections require a slightly smaller dataset due to projections being absent when the starting kicker is uncertain and our exclusion of games where the kicker was injured in-game. But most of our models still post a modest improvement in prediction during 2023 compared to those provided by league sites using RMSE as our metric. Given their performance with the test data (and the comparatively short running time), I would lean on one of the regression methods for future projections.
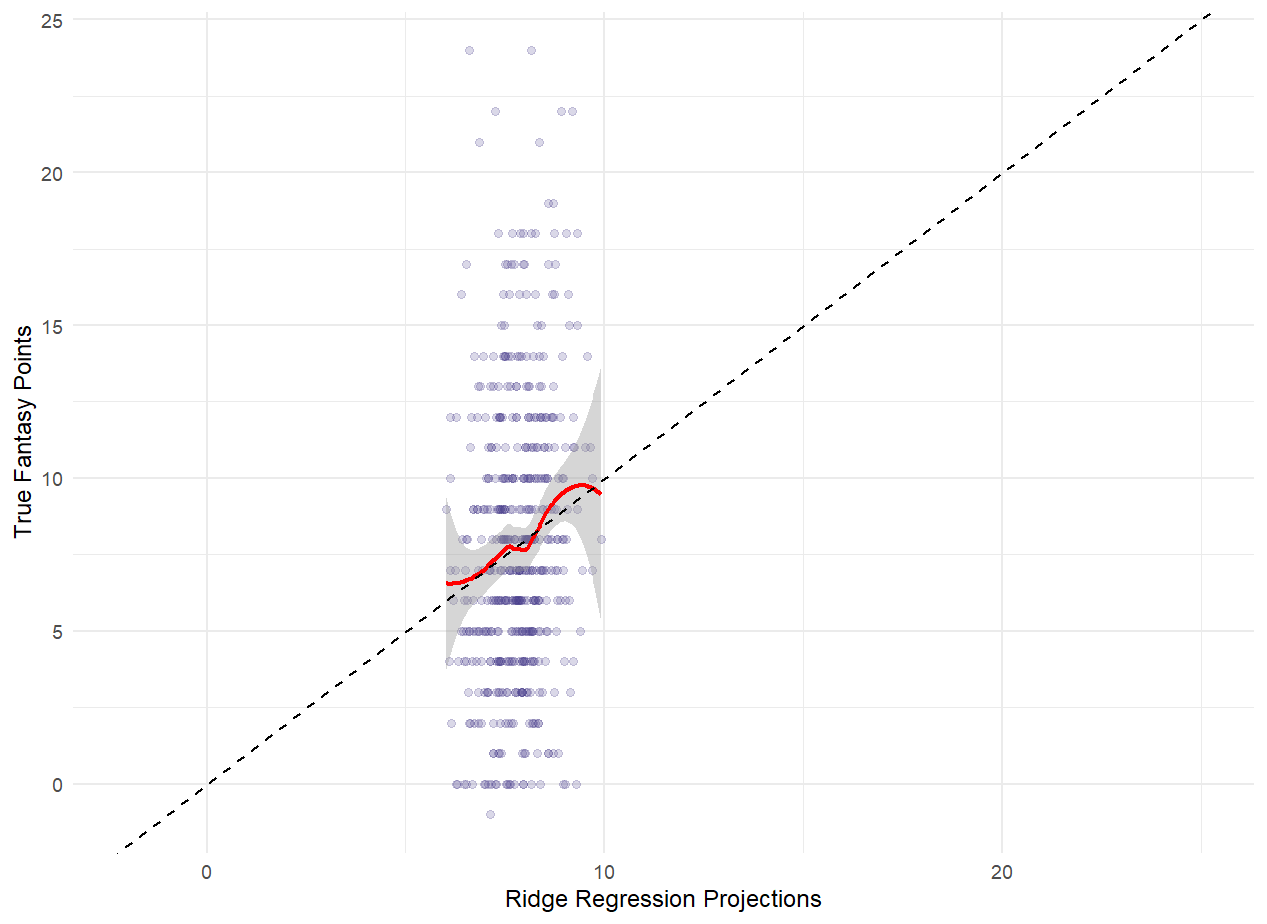
Initially, I was surprised we couldn’t do better given the amassed firepower of seven different machine learning methods of prediction. But it is a testament to how unpredictable these games truly are. Even when we give our top performing model, the ridge regression, the actual final score of the game, the RMSE (4.10) nets only an additional 11% improvement, so even a talented psychic can only help predict these kicker performances so much. Tree-based methods do a fair bit better with the extra info (RF = 3.76, 21% smaller). This may be in part because for certain smaller point totals, tree methods can more accurate attribute points to kickers because few possibilities exist, with only distance and the odd safety causing some variation.
Final Model
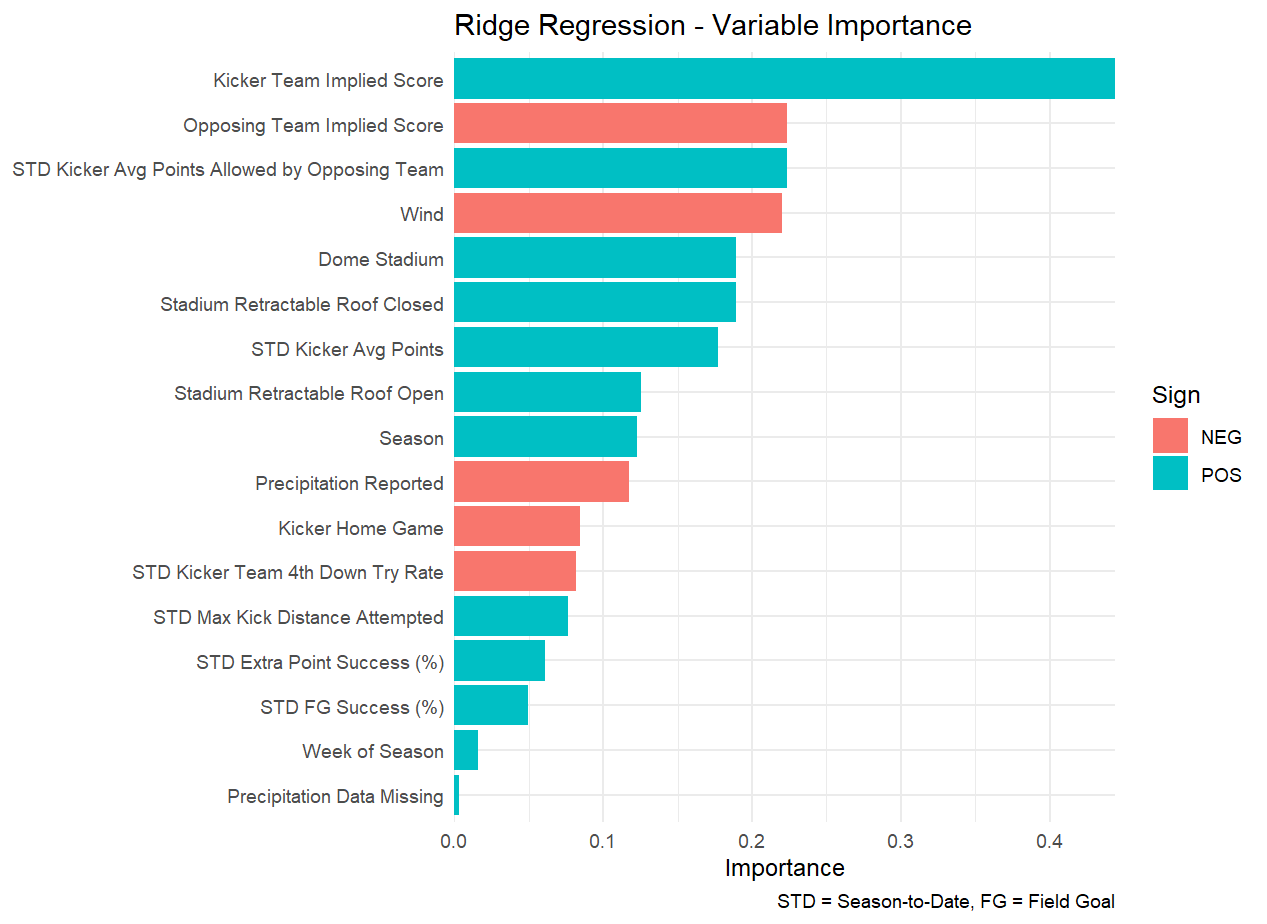
As for the model itself, a look at the variable importance stats puts the expected score of the team’s kicker at the top of this list, with other predictors being markedly less important. I could say I was surprised by the lack of predictive ability from the kicker accuracy metrics, but on the whole, NFL kickers are fairly accurate (kicker season FG percentage mean = 84.6%, SD = 7.8%), so it’s probably difficult to differentiate between those on the higher and lower end earlier in the season, and those that are more inaccurate are more likely to be cut and replaced. As for the direction of the relationships between the predictors, there again weren’t any grand surprises. Wind and precipitation appeared detrimental to kicker totals, while arenas that offered protection from the elements aided them. Higher historical kicker totals and defense-specific kicker point totals correlated with higher totals for that game.
Closing Remarks
This project may be worth revisiting with some additional information or inspiration. But in trying to both improve model fit and overfitting, we’ve tested variations such as using a smaller time frame for the training data, using more and less predictors, varying the threshold where imputed values were applied instead of cumulative averages, extending cumulative averages for kicker accuracy beyond one season, and changing the iterations used by the different machine learning models, all without tangible benefit to test set model fit. We also shifted our metric of interest to r-squared with the reasoning that we can tolerate consistent over- or under-prediction as long as the model can correlate with actual values strongly enough to inspire confidence as to the ranking of kickers in relation to each other, without seeing much change in our predictive ability. In the end, we’ve manufactured a model which can be called an improvement, but isn’t yet set to strongly protect against the frustration of selecting a poor-scoring kicker outing.